
My favorite function is 
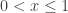
Most folks will get their calculator out and graph the function on the interval

Two zeros: one at 1 and the other about 0.05 more or less.
So then I suggest they look at 
Sure enough there is the zero near 0.05 but there is another near 0
So another window


Pretty soon they get the idea. Every time we stretch out the graph, there are more roots.
What is going on? The first thing is that this is not a question to be answered on a graphing calculator, the nice graphs notwithstanding.
So try to solve it by hand. Since 
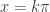

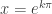

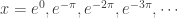
Why can’t we see the zeros on the graph?
This is not a calculator glitch; in fact computers can do no better. Each root is the next largest root divided by 

The calculator screen is made up of pixels. The number you choose for xmin is the center of the column of pixels; the number you choose for xmax is the center of the right-most column of pixels. The distance between the two ends is divided and assigned evenly to the centers of the other columns of pixels. The y-coordinates of the pixels are calculated the same way. The calculator evaluates the function at each pixel value and turns on the pixel in that column closest to (rarely at) the function’s value. A lot can go on between the pixels and the graphing calculator and its operator will not see what is happening there.
In this example, all the missing roots are between the first and second pixels on the left! When you change xmax to see the left 10% of the screen you see one and every now and then two roots, but the rest are still between the two pixels on the left.
Would a wider screen help? Perhaps a little, but not much.
Here’s a good exercise for a class: Suppose you could print the graph on a paper 1 mile (5280 feet) wide with the root at x = 1 on the right edge. Where would the next several roots be?
-
is 228.169 feet from the left edge
-
is 9.860 feet from the left edge
-
is 0.426 feet or 5.113 inches from the left edge
-
is 0.221 inches from the left edge (less than ¼ inch)
- And all the remaining roots are within 0.00955 inches from the left edge.
If the paper stretched from the earth to the sun you could see a few more. At 93,000,000 miles, the zero at 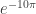
So why do I like this problem?
Look at all the math we did.
- We learned that graphing is not always the path to the answer.
- We learned how calculators choose the points they graph, and which they miss.
- We practiced how to solve a trig equation.
- We practiced how to solve a natural logarithm equation.
- We consider the actual size of the negative powers of e and saw how they got exponentially smaller.
- We did a practical problem in scaling to illustrate how fast the numbers diminish.
Why do I like this function?
What’s not to like?
Update (February 7, 2015) Chip Rollinson made this cool Geogebra applet to illustrate My Favorite Function. Use the slider on the screen and notice the x-axis scale as it changes. Thank you, Chip.
 so its inverse will contain points of the form
so its inverse will contain points of the form  , which, since we like the first coordinate of functions to be x, we may also call
, which, since we like the first coordinate of functions to be x, we may also call  , where ln(x) will be the name of the inverse of ex. Remember, at the moment ln(x) is just a notation for the inverse of ex, we do not know anything about logarithms (yet).
, where ln(x) will be the name of the inverse of ex. Remember, at the moment ln(x) is just a notation for the inverse of ex, we do not know anything about logarithms (yet). . For example, (0, 1) is a point on eX, so (1, 0) is a point on the ln(x) function, and so ln(1) = 0.
. For example, (0, 1) is a point on eX, so (1, 0) is a point on the ln(x) function, and so ln(1) = 0.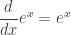 . Now, at
. Now, at  . That is
. That is


 and the t-axis between 1 and x. If
and the t-axis between 1 and x. If  , then
, then 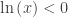 and if
and if 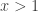 ,
,  .
.

 ,
,  and since ln(a) is a constant
and since ln(a) is a constant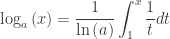
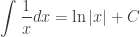 . The absolute value sign is to remind you that the argument of the logarithm function must be positive, since in some situations x itself may be negative.
. The absolute value sign is to remind you that the argument of the logarithm function must be positive, since in some situations x itself may be negative.