Continuing with some thoughts on helping students read math books, we will now look at the main things we find in them in addition to definitions which we discussed previously: theorems and axioms.
An implication is a sentence in the form IF (one or more things are true), THEN (something else is true). The IF part gives a list of requirements, so to speak, and when the requirements are all met we can be sure the THEN part is true. The fancy name for the IF part is hypothesis; the THEN part is called the conclusion.
Implications are sometimes referred to as conditional statements – the conclusion is true based on the conditions in the hypothesis.
An example from calculus: If a function is differentiable at a point, then it is continuous at that point. The hypothesis is “a function is differentiable at a point”, the conclusion is “the function is continuous at that point.”
This is often shortened to, “Differentiability implies continuity.” Many implications are shortened to make them easier to remember or just to make the English flow better. When students get a new idea in a shortened form, they should be sure to restate it so that the IF part and the THEN part are clear to them. Don’t let them skip this.
Related to any implication are three other implications. The 4 related implications are:
- The original implication: if p, then q.
- The converse is formed by interchanging the hypothesis and the conclusion of the original implication: if q, then p. Even if the implication is true, the converse may be either true or false. For example, the converse of the example above, if a function is continuous then it is differentiable, is false.
- The inverse is formed by negating both the hypothesis and the conclusion: if p is false, then q is false. For our example: if a function is not differentiable, then it is not continuous. As with the converse, the inverse may be either true or false. The example is false.
- Finally, the contrapositive is formed by negating both the original hypothesis and conclusion and interchanging them, if q is false, then p is false. For our example the contrapositive is “If a function is not continuous at a point, then it is it is not differentiable there.” This is true, and it turns out a useful. One of the quickest ways of determining that a function is not differentiable is to show that it is not continuous. Another example is a theorem that say if an infinite series, an, converges, then
 . This is most often used in the contrapositive form when we find a series for which
. This is most often used in the contrapositive form when we find a series for which  ; we immediately know that it does not converge (called the nth-term test for divergence).
; we immediately know that it does not converge (called the nth-term test for divergence).
The original statement and its contrapositive are both true or both false. Likewise, the converse and the inverse are both true or both false.
Any of the 4 types of statements could be taken as the original and the others renamed accordingly. For example, the original implication is the converse of the converse; the contrapositive of the inverse is the converse, and so on.
Definitions are implications for which the statement and its converse are both true. This is the real meaning of the reversibility of definitions. For this reason, definitions are sometimes called bi-conditional statements.
Axioms and Theorems
There are two kinds of if …, then… statements, axioms (also called assumptions or postulates) and theorems. Theorems can be proved to be true; axioms are assumed to be true without proof. A proof is a chain of reasoning starting from axioms, definitions, and/or previously proved theorems that convince us that the theorem is true. (More on proof in a future post.)
It would be great if everything could be proved, but how can you prove the first few theorems? Thus, mathematical reasoning starts with (a few carefully chosen) axioms and accepts them as true without proof. Everything else should be proved. If you can prove it, it should not be an axiom.
Theorems abound. All of the important ideas, concepts, “laws” and formulas of calculus are theorems. You will probably see few, if any, axioms in a calculus book, since they came long before in the study of algebra and geometry.
Learning Theorems
When teaching students and helping them read and understand their textbook, it is important that they understand what a theorem is and how it works. They should understand what the hypothesis and conclusion are and how they relate to each other. They should understand how to check that the parts of the hypothesis are all true about the function or situation under consideration, before they can be sure the conclusion is true.
For the AP teachers this kind of thing is tested on the exams. See 2005 AB-5/BC-5 part d, or 2007 AB-3 parts a and b (which literally almost no one got correct). These questions can be used as models for making up your own questions of other theorems.



 I figured it out this way
I figured it out this way
 This is a more formal way of what I did. (The solution k = 6 gives the same expression.) But the real question is how is a student supposed to know any of this? My friend wrote, “This problem seems really complicated for multiple=choice. Remember that this is what we had to do AFTER we had done law of cosines to get to that first step.” I agree. Then I asked her for the original problem, which is what I should have done in the first place. The original problem was to find the base of an isosceles triangle with a vertex angle of 30o and congruent sides of 2. Well that’s a whole different story:
This is a more formal way of what I did. (The solution k = 6 gives the same expression.) But the real question is how is a student supposed to know any of this? My friend wrote, “This problem seems really complicated for multiple=choice. Remember that this is what we had to do AFTER we had done law of cosines to get to that first step.” I agree. Then I asked her for the original problem, which is what I should have done in the first place. The original problem was to find the base of an isosceles triangle with a vertex angle of 30o and congruent sides of 2. Well that’s a whole different story: 
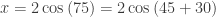

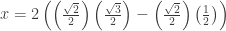


 Then using the Pythagorean Theorem on the lower triangle:
Then using the Pythagorean Theorem on the lower triangle: 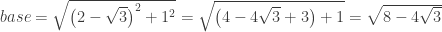
 . I like to ask folks how many zeros this function has on the interval
. I like to ask folks how many zeros this function has on the interval 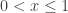 .
.
 . This is the left 10% of the first window.
. This is the left 10% of the first window.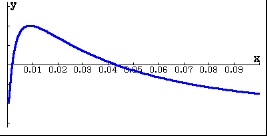


 for
for 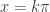 where k is an integer, we need to see when
where k is an integer, we need to see when  . That will be when
. That will be when 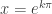 . And since our domain is proper fractions it must be that
. And since our domain is proper fractions it must be that  . So the zeros are infinite in number, namely
. So the zeros are infinite in number, namely 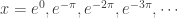 . Which answers the original question but raises others.
. Which answers the original question but raises others. . So each root is about
. So each root is about  of the larger next root.
of the larger next root. is 228.169 feet from the left edge
is 228.169 feet from the left edge is 9.860 feet from the left edge
is 9.860 feet from the left edge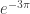 is 0.426 feet or 5.113 inches from the left edge
is 0.426 feet or 5.113 inches from the left edge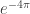 is 0.221 inches from the left edge (less than ¼ inch)
is 0.221 inches from the left edge (less than ¼ inch)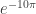 is about 0.134 inches from the edge.
is about 0.134 inches from the edge.
 , Answer including work:
, Answer including work:  . But I think a longer way around is also better:
. But I think a longer way around is also better: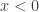 then
then  so
so  or if
or if 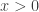 , then
, then  Solution:
Solution: 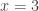 or
or  that it will be natural to say
that it will be natural to say so
so  or if
or if  Solution:
Solution: 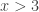
 . Starting the same way
. Starting the same way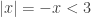 so
so 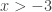 which really means
which really means 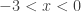
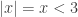 which really means
which really means  . Then the union of these two sets looks like an intersection. The solution is
. Then the union of these two sets looks like an intersection. The solution is 
 on the other side, with > you have a union pointing away from the origin and with < you have somehow an intersection. Who needs to remember all that when this idea works all the time?
on the other side, with > you have a union pointing away from the origin and with < you have somehow an intersection. Who needs to remember all that when this idea works all the time?
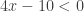 , then
, then  and
and 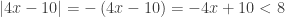 , so
, so  and
and  or more precisely
or more precisely 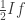 latex 4x-10\ge 0$, then
latex 4x-10\ge 0$, then  and
and 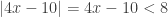 , so
, so  and
and  or more precisely
or more precisely  . The union again becomes an intersection and the answer is
. The union again becomes an intersection and the answer is 
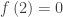 . After separating the variables, integrating, including the “+C” and substituting the initial condition students arrived at this equation which they now need to solve for y:
. After separating the variables, integrating, including the “+C” and substituting the initial condition students arrived at this equation which they now need to solve for y:


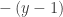 and then go ahead and solve for
and then go ahead and solve for 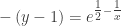

 , and all the angles add up to a straight angle, and lots of other great things, but for the definition we only mention the feature that distinguishes equilateral triangles from other triangles. It would be possible to use instead the 3 congruent angles or the fact that all three angles measure are
, and all the angles add up to a straight angle, and lots of other great things, but for the definition we only mention the feature that distinguishes equilateral triangles from other triangles. It would be possible to use instead the 3 congruent angles or the fact that all three angles measure are 